During data engineering projects I tend to try and minimize the tools being used. I think it’s a good practice. Having too many tools causes sometimes for errors going unnoticed by the teams members.
One of the advantages of having a tool like Databricks is that it
allows us to use all the power of python and avoid, like I did in
the past, to have something like Azure Functions to compensate for
the limitations of some platform.
Pre-requisites
Here’s a list of the things you need/should have:
ServicePrincipal
This one is kind of mandatory if you want the process to run unattended. You should create one and give it the following permissions:
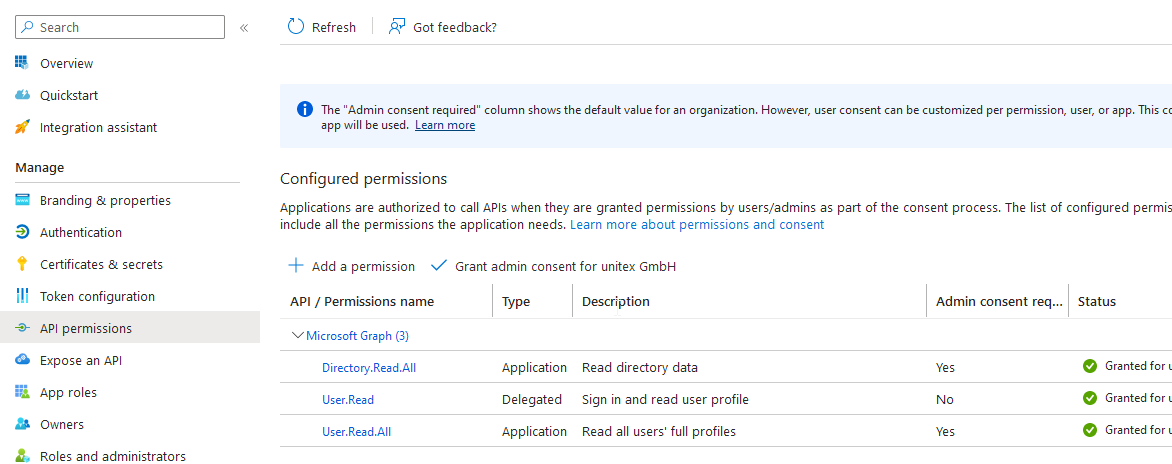
You’ll need some administrative permissions, so if you don’t have it ask your AAD admin to help you with that.
Azure Key Vault
This one is not mandatory but you should have it. There’s no need to have credentials in clear text anywhere, specially when this is so cheap to use.
The code
Getting secrets from AZure key Vault
This is so simple as:
appid = dbutils.secrets.get(scope = "AzureKeyVault", key = "ServicePrincipalId")
appsecret = dbutils.secrets.get(scope = "AzureKeyVault", key = "ServicePrincipalSecret")
tenantid = dbutils.secrets.get(scope = "AzureKeyVault", key = "TenantId")
Get the authentication token
Just import the requests python library, and use the function below. This will return the token you can then use to get the data.
import requests
def get_auth_token(tenantid, appid, appsecret, granttype="client_credentials", authority = "https://login.microsoftonline.com", apiresource = "https://graph.microsoft.com"):
tokenuri = f"{authority}/{tenantid}/oauth2/token?api-version=1.0"
body = [("grant_type", granttype), ("client_id", appid), ("resource", apiresource), ("client_secret", appsecret)]
token = requests.post(tokenuri, data=body)
return token.json()['access_token']
Get the data
You can edit the graph_call so that you can obtain the data you’re
interested. You can test it on the official Microsoft Graph Explorer.
This now is quite simple, we obtain the token by calling
get_auth_token, inject the token in the header of the call, looping
while we have data and in the end save it to a dataframe.
graph_url = "https://graph.microsoft.com/beta"
graph_call = f"{graph_url}/users?$select=id,displayName,UserPrincipalName"
token = get_auth_token(tenantid = tenantid, appid = appid, appsecret = appsecret)
headers = { 'Content-Type': 'application/json', 'Authorization': f"Bearer {token}" }
graph_results = []
while graph_call:
try:
response = requests.get(graph_call, headers = headers).json()
graph_results.extend(response['value'])
graph_call = response['@odata.nextLink']
except:
break
df = spark.read.json(sc.parallelize(graph_results))
#df.write.mode("overwrite").saveAsTable("temp.AAD_extraction")
display(df)
Conclusion
And that’s it. Easy peasy. Only thing left to make this entreprise ready would be to deal with the throttling. This should work for most of the tenants out there. You really have to be dealing with a massive AAD to hit the limits while doing this kind of extraction.
Have fun!